T1 手撕STL sort
问题描述
模拟实现C++中STL sort的功能。
设数组 中有 个元素,有三个要求。
- 当递归区间小于设定值时,直接返回。
- 当递归深度超过 时,转为堆排序。
- 最后对整个数组进行直接插入排序。
题解
这题解法都已经给好了,就对着书上把相应的代码抄下来,然后按照题意组合就行了。注意若区间足够小,一定是先返回,只有当要求 不满足时,才考虑堆排序。
T2 冬奥会接驳车
问题描述
一个 的矩阵,其中每个元素为, 空地, 障碍, 起点, 终点。
一个人从起点出发,只能上下左右移动,不能碰到障碍,求最少几步能够到终点。
题解
显而易见的 问题,从起点开始,每次向四个方向扩展,走到的地方如果不是障碍且步数更少就入队,直到走到终点即可。如果所有元素出队后,终点仍未入队(没走到),则无解。
(X,Y) => 队列Q;
dis(X,Y) = 0; //起点入队,dis记录步数
while (head < tail) //队列不空
{
Q => (X,Y);
for (int i = 0; i < 4; ++i)
{
(X,Y) + next[i] -> (x,y); //向四个方向扩展
if (x,y)未过边界 && (x,y)不是障碍 && (dis(X,Y) + 1 < dis(x,y))
{
dis(x,y) = dis(X,Y) + 1;
(x,y) => Q; //新点入队
}
}
}时间复杂度 。
T3 自动纠错
问题描述
两个字符串 之间的距离 定义为,有三种操作:
- 删去任意位置一个字符
- 增加任意位置一个字符
- 改变任意位置一个字符
改变为 所需要的最小的操作次数,为两者间的距离。如图所示的距离(上 ,下 )为 。
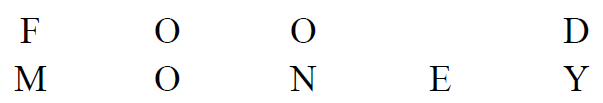
现有一个字典,其中有 个元素,每个元素为字符串 和其对应的频率 。
给出 个询问,每个询问为一个字符串 ,问字典中哪些字符串和 的距离在 之内,并输出其中频率最高的(频率相同时字典序更小)。
题解
数据结构
具体的数据结构题目已经很明显的给出了:
一种高效的处理方法是:结合各单词间的距离,将字典组织成一棵多叉树。在该树中,每个结点表示一个单词,对于每个结点 ,其第 棵子树包含与 的距离为 的所有单词对应的结点。
树的创建过程如下:取字典中任意单词作为根结点,比如第一个单词。然后将剩余单词逐个插入到树中,插入一个新单词 时,首先计算该单词与根结点的距离 。若根结点的第 个子树为空,则将单词 对应的结点作为根结点的第 个子结点。若根结点的第 个子树非空,即根结点已有第 个子结点 。则按上述规则将单词 递归插入以 为根的子树,即计算 与 的距离…。
例如字典为 ,将 作为根结点,然后将 插入, 与 的距离为 ,故 作为 的第一个子结点。 与 的距离为 ,故 作为 的第 个子结点。如下图 所示。
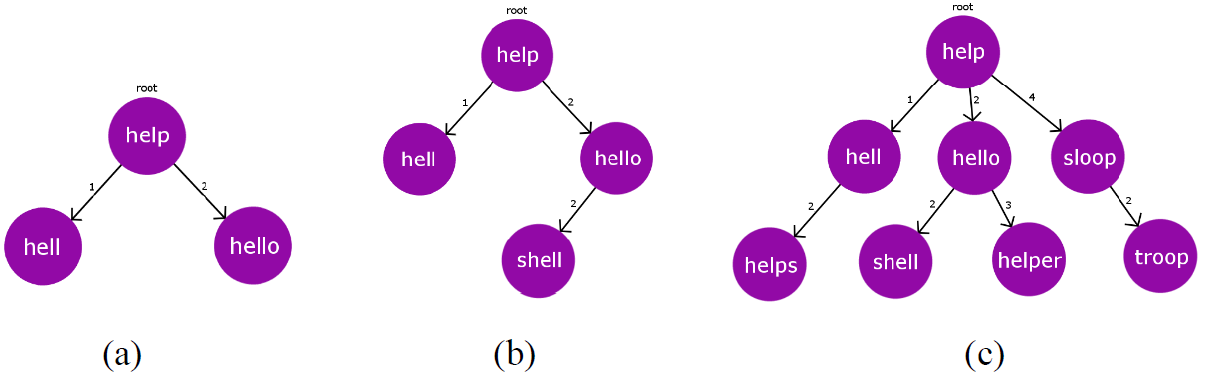
然后插入 与 的距离为 ,故应在 的第 个子树里,但 已经有第 个子结点 了,此时将 递归插入以 为根结点的子树:计算 与 的距离为 ,将 作为 的第 个子结点,如上图 所示。插入 时, 与 的距离为 ,将 递归插入以 为根结点的子树:计算 与 的距离为 ,将 作为 的第 个子结点。以此类推,最终上述字典对应的树结构如上图 所示。该树结构保证与任意结点距离为 的单词都在该结点的第 棵子树里。
假定我们需要向用户返回与错误单词距离不超过 的单词,当用户输入一个单词 时,在树中查询 ,计算 与根结点 的距离 ,接下来我们不必考察 的所有子树中是否包含与 距离不超过 的结点/单词,而只需要递归考察根结点 的第 到第 棵子树即可。例如 ,我们只需要递归考察根 的第 、第、第棵子树是否包含与距离不超过的结点/单词。其他子树无需考察,为什么呢?举个例子,我们考虑根的第棵子树的任意结点。与的距离为,即最少经过步操作才能转换为,与的距离为,经过最少步操作才能变为,这意味着至少需要步操作才能变为。不可能通过步操作变为。故第棵子树的所有结点都不满足条件。
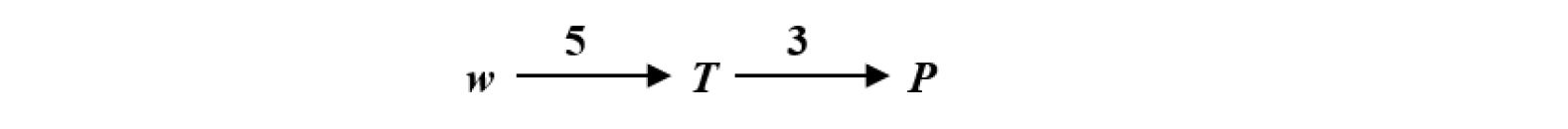
由于通常很小,因此该方法在查询时往往可以排除很多子树,进而节省时间。当考察一个结点时,计算与该结点的距离;若,意味着用户输入的单词在字典中,是正确的单词;若则该结点不是候选单词,继续递归考察该结点第到的子树。若则该结点就是候选单词之一,此时可有两种策略,一是将该单词直接返回给用户,二是继续向下考察子树,找出所有候选单词并选择用户历史使用频率最高的单词返回给用户。
以上为题目给出的算法,注意这个算法时间复杂度并不严格,只是能在某种程度上减少比较次数,但可以确保通过此题(需注意实现算法的常数)。
计算字符串距离
除此以外,还有一个重要的问题就是,如何计算两个字符串的距离。
可见每个位置都有三种操作,如果直接暴力比较,虽然字符串的长度只有 ,也仍然需要 次比较,显然是无法接受的。
这里提出一种有效的解决方案,这个问题可以使用动态规划解决。
设 为 考虑到 位置, 考虑到 位置,$s1_{1 \cdots i},s2_{1 \cdots j} $ (前缀)的距离。显然对于 有两种情况:
- ,此时
- ,此时
对于 很好理解,两个位置相同,就没必要操作,直接从之前的状态扩展即可。
对于 ,三个式子正好对应三种操作(改变,增加,减少),因为要次数最少,所以取三者最小值,再加上一次操作次数,拓展到新状态。
边界条件可根据状态得出:
- 显然 是空,则 最少通过减 个字符与其相同。
- 同上。
int Dis(char *s1, char *s2)
{
int len1 = strlen(s1);
int len2 = strlen(s2);
int dp[Max_len][Max_len] = {0};
int len = max(len1, len2);
for (register int i = 0; i <= len; ++i)
dp[i][0] = dp[0][i] = i; //边界条件
for (register int i = 1; i <= len1; ++i)
for (register int j = 1; j <= len2; ++j)
if (s1[i - 1] == s2[j - 1])
dp[i][j] = dp[i - 1][j - 1]; //情况1
else
dp[i][j] = min(dp[i - 1][j - 1], min(dp[i - 1][j], dp[i][j - 1])) + 1; //情况2
return dp[len1][len2];
}时间复杂度 , 为字符串长度。